| English | Japanese |
|
|
昨日までのアクセス |
| はじめに | 【 リリー日記 】 ミンダナオでの生活日記 |
| 25/12/28 | スマフォでも記事検索が出来るようになりました |
| 25/12/10 | ケンプロKR-500コネクタ改造 |
| 25/12/06 | サテライト用ポールの設置 |
| 25/12/03 | KR-400にKR-500を取り付け |
| 25/11/20 | 衛星トラッキングソフトウエア "Sat Track 開発バージョン" |
| 25/11/19 | EMSでケンプロKR-400到着 |
| 25/11/18 | 3.5MHzアンテナトロイダルコア |
| 25/11/16 | WiMO V/UHFクロス八木 |
| 25/11/16 | WSJT-X自動運用Ver0.1.1 |
| 25/11/09 | コタバトでDU9JJYとアイボール |
| 25/11/04 | APRS用TNCソフトウェアVer1.2 |
| 25/11/03 | インドネシア衛星IO-86イベント |
| 25/10/29 | アクティブサテライトリスト |
| 25/10/24 | FTDX3000修理完了 |
| 25/10/17 | ケンプロ KR-500修理完了 |
| 25/10/15 | ARISS SSTV DIPLOMA |
| 25/10/14 | 国際宇宙ステーションの情報 |
| 25/10/13 | ST2でACモーターローテ―ターを駆動する |
| 25/10/12 | 国際宇宙ステーションからのAPRS信号を受信 |
| 25/10/11 | APRS用TNCソフトウェア使い方編 |
| 25/10/10 | APRS用TNCソフトウェア |
| 25/10/09 | 近視眼鏡を作る |
| 25/10/09 | IC-820H PLL UNLOCK修理 |
| 25/10/05 | 435MHzクロス八木製作準備 |
| 25/10/04 | 国際宇宙ステーションの SSTVの受信に成功 |
| 25/10/03 | 仰角ローテーターKR-500の修理 |
| 25/10/02 | 145MHzクロス八木製作準備 |
| 25/10/01 | ISSのAPRS信号を受信成功 |
| 25/09/29 | CQ WW RTTYコンテスト |
| 25/09/27 | 国際宇宙ステーションからのSSTV |
| 25/09/26 | WARCバンドのファンアウトアンテナ |
| 25/09/25 | 仰角ローテーターKR-500ゲット |
| 25/09/23 | DireWolf をHamlib 込みビルドする手順 |
| 25/09/23 | TNC direwolfソフトウェア |
| 25/09/21 | RS-44ビーコン受信成功 |
| 25/09/20 | 車に無線機を取り付け |
| 25/09/18 | ST2 設定 & SatPC32 セットアップガイド |
| 25/09/17 | DH1NGP Peterの無線車 |
| 25/09/16 | FM衛星の始め方(翻訳) |
| 25/09/14 | AutoCWType_Ver1.5.9 |
| 25/09/13 | 3.5MHzSWRが上昇 |
| 25/09/12 | 3.5MHzツエップアンテナの調整 |
| 25/09/10 | 静止衛星 QO-100 |
| 25/09/09 | サテライト局の準備に向けて |
| 25/09/08 | DU9JJY サテライト局 |
| 25/09/07 | 深夜の14MHz |
| 25/09/03 | 三菱ピックアップ ストラーダ― オイル交換 |
| 25/08/18 | WSJT-X自動運用Ver0.1.0 |
| 25/08/18 | JTDX自動運用Ver0.6.3 |
| 25/08/10 | ソフトウェア一覧 |
| 25/07/26 | AutoCWType_Ver1.5.8 |
| 25/07/20 | JTDXから1ヶ月分のADIF ファイルを作る log_reciver_Ver2.6.5 |
| 25/07/19 | 電波利用料納付完了 |
| 25/07/13 | IARU HF Contest |
| 25/07/10 | ソフトウェアのアップデート |
| 25/07/08 | DXV500ZSリニアアンプ修理 |
| 25/07/07 | CQマシーンプログラム |
| 25/06/21 | LoTWシステムアップグレード |
| 25/06/18 | 3.5MHz用RG8到着 |
| 25/06/15 | 時刻合わせ Ver0.5 |
| 25/06/14 | Drone Habsan ZINO到着 |
| 25/06/12 | フィリピン独立記念日 |
| 25/06/11 | アルジェリア 7X2RFのQSLカード |
| 25/06/10 | 翻訳APIプログラム |
| 25/06/09 | DXCC150の賞状到着 |
| 25/06/08 | AutoCWType_Ver1.4.1 |
| 25/06/07 | シャックの様子をご紹介 |
| 25/06/06 | ChatGPTに描いてもらった似顔絵 |
| 25/05/26 | Windows全角半角切り替え |
| 25/05/17 | OK2ZAW BCD to 16 converter |
| 25/05/16 | 3.5MHzツェップアンテナ用 ステッピングモーターあれこれ |
| 25/05/15 | 3.5MHzステッピングモーター計画 |
| 25/05/14 | 3.5MHz同調コイル取り付け |
| 25/05/11 | 3.5MHzアンテナ設置完了 |
| 25/05/03 | JTDX自動運転プログラムVer0.4.3 |
| 25/04/26 | Drone Habsan ZINO |
| 25/04/25 | 時刻合わせ Ver0.3 |
| 25/04/24 | AutoCWType_Ver1.3 |
| 25/04/23 | FTDX3000液晶修理準備 |
| 25/04/22 | 3.5MHzツエップアンテナの設置計画 |
| 25/04/21 | AutoCWType_Ver1.1 |
| 25/04/20 | 10,14MHzアンテナ設置完了 |
| 25/04/19 | JTDX自動運転プログラムVer0.4.1 |
| 25/04/19 | 14MHzのアンテナポール設置 |
| 25/04/18 | ThinkPad X390修理完了 |
| 25/04/17 | 検索が出来るようになりました |
| 25/04/15 | 10MHzダイポールの準備 |
| 25/04/12 | Hexbeam Part8 |
| 25/04/06 | ThinkPad X390が壊れた |
| 25/04/05 | 時刻合わせプログラム |
| 25/03/31 | JTDX自動運転プログラム |
| 25/03/30 | CWTypeからHamlogへ自動ログ送信 |
| 25/03/21 | Hexbeam Part7 |
| 25/03/20 | FreeDV Part3 初QSO |
| 25/03/18 | FreeDV Part2 シャック内QSO |
| 25/03/16 | Hexbeam Part6 |
| 25/03/15 | FreeDV Part1インストール |
| 25/03/09 | Hexbeam Part5 |
| 25/03/07 | Hexbeam Part4 |
| 25/03/05 | 28MHzアンテナ改造 |
| 25/03/01 | FTDX3000が壊れた! |
| 25/02/28 | 50MHzFT8でパイルアップ |
| 25/02/28 | DXV500ZSリニアアンプ修理 |
| 25/02/27 | タワーのパイプ・立て直し計画 |
| 25/02/26 | Ozamizからの日本の方角 |
| 25/02/26 | 28MHzが飛ばない |
| 25/02/23 | DXV500ZSリニアアンプ修理 |
| 25/02/22 | Hexbeam Part3 |
| 25/02/21 | Hexbeam Part2 |
| 25/02/18 | 28MHzアンテナ工事 |
| 25/02/17 | 18,24MHzアンテナ高さ工事 |
| 25/02/16 | Z26NS Cosovo |
| 25/02/14 | 21MHz FT8 |
| 25/02/12 | 7,21MHzのアンテナ修理 |
| 25/02/08 | 21MHzでCWを運用 |
| 25/02/05 | DXV500ZSリニアアンプ故障 |
| 25/01/19 | Input Director |
| 25/01/14 | テンポラリーライセンス更新 |
| 検索が出来るようになりました (2025/04/17) | ||
|---|---|---|
| 以前からやりたかった日記の検索が出来るようになりました 「記事検索」にフリーワードを入れると該当する記事一覧が表示されます  |
||
検索結果のリンクをクリックすると該当日記が開きます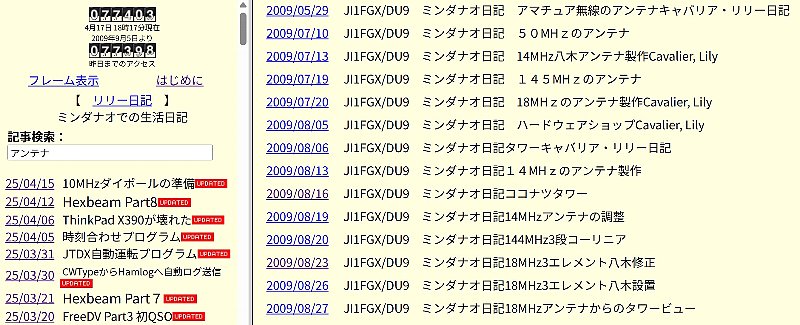 |
||
| ChatGPTに相談するとレンタルサーバーXserverのPythonのバージョンが Python 2.7.5で既にサポートが終わっているからバージョンアップしろとの指示 ところがPython-3.12.3のインストールがエラーで終わらない そうしたらgcc バージョン 4.8.5で古いからgccのバージョンアップをしろとの指示 結局夕方から朝までmakeに時間がかかってしまいました。 |
||
| # GCC インストール手順 echo $HOME /home/lily2004 # 作業ディレクトリ作成 mkdir -p $HOME/src cd $HOME/src # MPFR, GMP, MPC のソースをダウンロードしてインストール wget https://ftp.gnu.org/gnu/gmp/gmp-6.2.1.tar.xz tar xf gmp-6.2.1.tar.xz cd gmp-6.2.1 ./configure --prefix=$HOME/local make make install cd .. wget https://www.mpfr.org/mpfr-4.2.1/mpfr-4.2.1.tar.xz tar xf mpfr-4.2.1.tar.xz cd mpfr-4.2.1 ./configure --prefix=$HOME/local --with-gmp=$HOME/local make make install cd .. wget https://ftp.gnu.org/gnu/mpc/mpc-1.2.1.tar.gz tar xf mpc-1.2.1.tar.gz cd mpc-1.2.1 ./configure --prefix=$HOME/local --with-gmp=$HOME/local --with-mpfr=$HOME/local make make install cd .. # GCCのダウンロード wget https://ftp.gnu.org/gnu/gcc/gcc-11.4.0/gcc-11.4.0.tar.xz tar xf gcc-11.4.0.tar.xz cd gcc-11.4.0 # 必要な環境変数の設定(パスの追加など) export PATH=$HOME/local/bin:$PATH export LD_LIBRARY_PATH=$HOME/local/lib:$LD_LIBRARY_PATH export CFLAGS="-I$HOME/local/include" export LDFLAGS="-L$HOME/local/lib" # GCCのビルド準備 ./configure --prefix=$HOME/local --with-gmp=$HOME/local --with-mpfr=$HOME/local --with-mpc=$HOME/local --enable-languages=c,c++ --disable-multilib make make install cd .. # Pythonのインストール準備 wget https://www.python.org/ftp/python/3.12.3/Python-3.12.3.tgz tar xf Python-3.12.3.tgz cd Python-3.12.3 # Pythonの環境設定 export LD_LIBRARY_PATH=$HOME/local/lib64:$LD_LIBRARY_PATH export CFLAGS="-I$HOME/local/include" export LDFLAGS="-L$HOME/local/lib" # Pythonのビルドとインストール ./configure --prefix=$HOME/local --enable-optimizations --with-ensurepip=install make make install cd .. # Pythonの確認 /home/lily2004/local/bin/python3.12 --version # 必要に応じてpipのアップグレード /home/lily2004/local/bin/python3.12 -m ensurepip --upgrade |
||
| gccのMakeが終わって作ったCGI search_and_write.cgi # search_and_write.cgi #!/usr/bin/env perl use strict; use warnings; use utf8; use CGI; use JSON; use Encode; binmode(STDOUT, ":encoding(UTF-8)"); my $q = CGI->new; my $keyword = $q->param('keyword') // ''; $keyword = decode('UTF-8', $keyword) if defined $keyword; $keyword =~ s/^\s+|\s+$//g; print $q->header(-type => 'text/html', -charset => 'UTF-8'); print "<html><head><meta charset='UTF-8'><title>検索結果</title></head><body bgc olor=#ffffe0>"; print "<style>table { border-collapse: collapse; } td { padding: 4px 10px; verti cal-align: top; }</style>"; print "<p>キーワード = [$keyword]</p>"; if (!$keyword) { print "<p>キーワードが入力されていません。</p>"; print "</body></html>"; exit; } my $json_file = '/home/lily2004/ji1fgx.com/public_html/index.json'; if (-e $json_file) { open my $fh, '<', $json_file or die "ファイル読み込みエラー: $!"; my $json_data = do { local $/; <$fh> }; close $fh; my $data = decode_json($json_data); my @results = grep { ($_->{title} && $_->{title} =~ /\Q$keyword\E/i) || ($_->{content} && $_->{content} =~ /\Q$keyword\E/i) } @$data; if (@results) { print "<p>検索結果:</p><table border=0 cellpadding=0 cellspacing=0>"; foreach my $result (@results) { my $raw_title = $result->{title}; my $file = $result->{file}; my $path = '/' . $file; # titleにHTMLタグが含まれていたらプレーンテキストだけ取り出す my $title = $raw_title; $title =~ s/<[^>]*>//g; my ($date, $description) = ("", $title); if ($title =~ /[((]([^()()]*)[))]/) { my $paren_content = $1; if ($paren_content =~ /^\d{4}\/\d{2}\/\d{2}$/) { $date = $paren_content; $description =~ s/[((]$date[))]//; } } if ($date ne '') { print "<tr><td><a href=\"$path\" target=\"B\">$date</a></td><td> $description</td></tr>"; } else { print "<tr><td colspan=\"2\"><a href=\"$path\" target=\"B\">$tit le</a></td></tr>"; } } print "</table>"; } else { print "<p>検索結果は見つかりませんでした。</p>"; } } else { print "<p>index.jsonファイルが見つかりません。</p>"; } print "</body></html>"; |
||
| 目次部分に埋め込まれた<script> <script> window.addEventListener("DOMContentLoaded", function () { const searchBox = document.getElementById("searchBox"); searchBox.addEventListener("keydown", function(event) { if (event.key === "Enter") { event.preventDefault(); // フォームの送信やページリロードを防ぐ const keyword = searchBox.value; console.log("Enterキーが押されました。キーワード:", keyword); const encodedKeyword = encodeURIComponent(keyword); const url = `/script/search_and_write.cgi?keyword=${encodedKeyword}&_=${Date.now()}`; // フレーム名「B」に読み込ませる parent.frames["B"].location.href = url; } }); }); </script> <tr> <td colspan="2"> <form method="get" accept-charset="UTF-8"> <label for="searchBox"><strong>記事検索:</strong></label> <input type="text" id="searchBox" name="keyword" placeholder="キーワードを入力してください" size="35"> <!-- <input type="submit" value="検索">--> </form> <div id="results" style="margin-top: 10px;"></div> </td> </tr> |
||
| Json Index (index.json) を作るPythonのプログラムmake_index.2.py cronで1日に一回動かしています 0 2 * * * /home/lily2004/local/bin/python3 /home/lily2004/ji1fgx.com/public_html/script/make_index.2.py /home/lily2004/ji1fgx.com/public_html /home/lily2004/ji1fgx.com/public_html/index.json # make_index.2.py # -*- coding: utf-8 -*- import os import json import sys import chardet from bs4 import BeautifulSoup # ファイルのエンコーディングを判定する関数 def detect_encoding(file_path): with open(file_path, 'rb') as f: raw_data = f.read() result = chardet.detect(raw_data) return result['encoding'] or 'utf-8' # 結果がない場合はutf-8を返す # HTMLから独自タイトルと本文を抽出する関数 def extract_custom_title_and_text(file_path): encoding = detect_encoding(file_path) # エンコーディングを検出 with open(file_path, 'r', encoding=encoding, errors='ignore') as f: html = f.read() soup = BeautifulSoup(html, 'html.parser') # 独自タイトル抽出 th_title = soup.find('th', class_='hpb-cnt-tb-th1') title = '' if th_title: title = th_title.get_text(strip=True) # 本文も抽出(検索用) body = soup.get_text(separator=' ', strip=True) return title, body def main(folder, output_file): index_data = [] for filename in os.listdir(folder): # if filename.endswith('.html', '.php'): if filename.endswith(('.html', '.php')): full_path = os.path.join(folder, filename) try: title, content = extract_custom_title_and_text(full_path) # ファイル名をリンクとして埋め込む link = f'<a href="{filename}" target="B">{filename}</a>' # データをindex_dataに追加 index_data.append({ 'title': title or link, 'file': filename, 'link': link, 'content': content[:300] }) except Exception as e: print(f"Error processing {filename}: {e}") with open(output_file, 'w', encoding='utf-8') as f: json.dump(index_data, f, ensure_ascii=False, indent=2) print(f"Index file created: {output_file}") if __name__ == '__main__': if len(sys.argv) < 3: print("Usage: make_index.py <input_folder> <output_file>") else: input_folder = sys.argv[1] output_file = sys.argv[2] main(input_folder, output_file) |
||
| 2024年04月15日 2025年04月18日 |