| English | Japanese |
|
|
Yesterdays access |
| Page Top | [Lily Diary.】 A diary of life in Mindanao. |
| 24/12/11 | CVS conversion software for DXCC listings |
| 24/12/05 | Aggregation by country from JTDX |
| 24/12/02 | ADIF for one month from JTDX Programs that create files |
| 24/11/24 | CwGet and CwType settings |
| 24/11/24 | WWDX Contest |
| 24/11/21 | CQ Ham Radio |
| 24/11/20 | Call Sign Assignment IOTA Number |
| 24/11/13 | IOTA 100 Awards Arrival |
| 24/11/12 | LoTW WAZ and DXCC |
| 24/11/04 | PLDT Optical Internet |
| 24/10/30 | Pile-up of 50MHz FT8 |
| 24/10/28 | Camiguin Is Crowdfunding |
| 24/10/26 | 50MHz Yagi feeder |
| 24/10/21 | RTTY with MMTTY |
| 24/10/19 | Firmware for UV-5K |
| 24/10/17 | Antenna group seen by drone |
| 24/10/16 | 7MHz Antenna Pole |
| 24/10/15 | 3.5MHz zepp transceiver antenna |
| 24/10/14 | Hexbeam Purchase Plan |
| 24/10/13 | 24MHz dipole addition |
| 24/10/13 | 50MHz Yagi repair completed 50MHz FT8 first pile |
| 24/10/12 | Antenna production for 24 MHz |
| 24/10/09 | Trouble with Gmail |
| 24/10/09 | The Shack |
| 24/10/07 | JO1CRA/7 AS-206 |
| 24/10/05 | 3D2V Rotuma Island IOC-060 |
| 24/10/01 | Camiguin Island Trailer Video |
| 24/09/30 | Uruguay |
| 24/09/29 | 50MHz antenna installation |
| 24/09/25 | Pile up on the caller's side |
| 24/09/19 | IOTA 100 Award |
| 24/09/18 | IOTA Application |
| 24/09/12 | DXCC Application |
| 24/09/11 | FT8 in communication with KH8T |
| 24/09/08 | 50MHz Yagi Antenna |
| 24/08/28 | Pile up at FT8 |
| 24/08/07 | Pile up from FT8EU |
| 24/07/19 | JW/WE9G in Svalbard |
| 24/06/27 | Purchase of air conditioner for wireless room |
| 24/05/28 | antenna switch |
| 24/05/27 | MFJ-259B Repair |
| 24/05/10 | Completed 3-band antenna |
| 24/05/03 | 7MHz Dipole |
| 24/04/30 | 7MHz Domestic |
| 24/04/29 | Reopening Project |
| 24/04/04 | Repair of FTDX3000 |
| 24/03/21 | To NTC Cagayan |
| Software to create CSV files from ARRL DXCC lists (December 11, 2024) | ||||
|---|---|---|---|---|
| DXCC files on the ARRL page. I found the PDF file, but I can't find the CSV file. Microsoft 365 Personal" is required to put PDF to WORD, which costs 1,284 yen/month. I copied and pasted the TEXT file that Mr. Sakurai taught me, but I can't put it on Excel properly. Click here for ARRL's DXCC list So I've been hooked since the other day.Python(Python) to create a conversion program. |
||||
Create CSV file from DXCClist.zip Download count: 1 4_ |
||||
| The program isPython(Python) programming language. I've tested the operation on a Windows 11 computer.python-3.13.0-amd64must be downloaded and installed. External libraries must be installed after Python (Python) installation |
||||
| This is the DXCC list you can see at ARRL. Can't download it, so copy and paste it into notepad or something and save it in UTF-8 as C:\Los\input.txt  |
||||
| Execution screen of TEXTtoCVS.0.0.4.py Forgive me if it is not GUI based. I'm in the middle of a strong on Tsutomu ChatGPT right now. 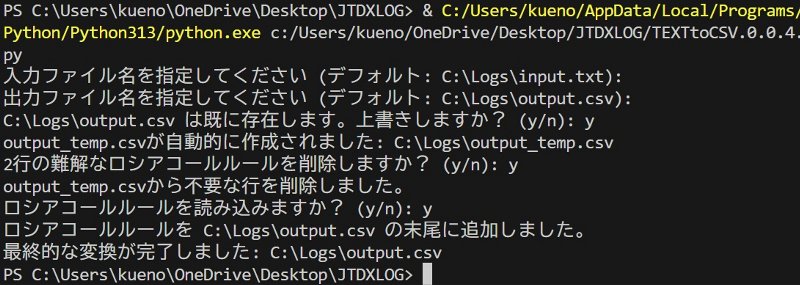 |
||||
| Readme.txt Software to create CSV files from text versions of ARRL's DXCC listings JI1FGX/DU9 Kouichi Ueno TEXTtoCSV.0.0.4.py Python installation is required to run TEXTtoCSV.0.0.4.py. To install Python, visit the official website (https://www.python.org/downloads/The process can be done from the following location The DXCC list can be found at this URL. The link is too long.Click here Download or copy and paste the file into a folder with the name input.txt. As a preliminary step, please remove the header text. The default save directory is C:\Logs. Please change it as you see fit. When executed, it will create a file named output.csv in the default directory. Remove the (numbers), *, #, and ^ contained in the text file to create a CSV file. The Russian call sign rules were difficult to understand, so we created our own list of rules. UA-UI1-7,RA-RZ* European Russia UA-UI8-0,RA-RZ* Asiatic Russia Files included in the package (all files must be saved in UTF-8) TEXTtoCSV.0.0.4.py This program input.txt Text file downloaded from ARRL output.csv Sample file after conversion Russia_Call_Rules.csv Please put it in the default directory Readme.txt Behind the Development Story The program itself is written by ChatGPT. I give them the specifications and they send back Python source code in response. We will also direct the addition of features and minor modifications. It took only a few minutes to convert a text file to CSV and remove unnecessary characters. However, ChatGPT had a hard time erasing one irregular character in the DXCC list. Specifically, T8,(21) with parentheses and comma deletion, which I was able to do immediately. Z6(1),(55) Lots of back and forth to get this comma. If you have them write this regular expression, it will erase even the necessary commas. It took half a day to revert back to a version that could handle the process correctly and have it written again and again. We made specific suggestions and finally it was done. |
||||
source code
|
||||