| English | Japanese |
|
|
昨日までのアクセス |
| はじめに | 【 リリー日記 】 ミンダナオでの生活日記 |
| 24/12/11 | DXCCリストのCVS化ソフト |
| 24/12/05 | JTDXから国別集計 |
| 24/12/02 | JTDXから1ヶ月分のADIF ファイルを作るプログラム |
| 24/11/24 | CwGetとCwTypeの設定 |
| 24/11/24 | WWDXコンテスト |
| 24/11/21 | CQ Ham Radio |
| 24/11/20 | コールサインの割り当てIOTA番号 |
| 24/11/13 | IOTA100アワード到着 |
| 24/11/12 | LoTW WAZとDXCC |
| 24/11/04 | PLDT光インターネット |
| 24/10/30 | 50MHzFT8のパイルアップ |
| 24/10/28 | Camiguin Is Crowdfunding |
| 24/10/26 | 50MHz八木給電部 |
| 24/10/21 | MMTTYでRTTY |
| 24/10/19 | UV-5Kのファームウェア |
| 24/10/17 | ドローンで見たアンテナ群 |
| 24/10/16 | 7MHzアンテナポール |
| 24/10/15 | 3.5MHzツェップアンテナ |
| 24/10/14 | Hexbeam 購入計画 |
| 24/10/13 | 24MHzダイポール追加 |
| 24/10/13 | 50MHz八木修理完了 50MHzFT8初パイル |
| 24/10/12 | 24MHzのアンテナ制作 |
| 24/10/09 | Gmailのトラブル |
| 24/10/09 | シャックの様子 |
| 24/10/07 | JO1CRA/7 AS-206 |
| 24/10/05 | 3D2Vロツマ島 IOC-060 |
| 24/10/01 | カミギン島予告ビデオ |
| 24/09/30 | ウルグアイ |
| 24/09/29 | 50MHzアンテナ設置 |
| 24/09/25 | 呼ぶ側のパイルアップ |
| 24/09/19 | IOTA100アワード |
| 24/09/18 | IOTAの申請 |
| 24/09/12 | DXCCの申請 |
| 24/09/11 | FT8でKH8Tと交信 |
| 24/09/08 | 50MHz八木アンテナ |
| 24/08/28 | FT8でパイルアップ |
| 24/08/07 | FT8EUからパイルアップ |
| 24/07/19 | SvalbardのJW/WE9G |
| 24/06/27 | 無線室のエアコン購入 |
| 24/05/28 | アンテナ切り替え器 |
| 24/05/27 | MFJ-259B修理 |
| 24/05/10 | 3バンドアンテナ完成 |
| 24/05/03 | 7MHzダイポール |
| 24/04/30 | 7MHz国内の様子 |
| 24/04/29 | 再開局プロジェクト |
| 24/04/04 | FTDX3000の修理 |
| 24/03/21 | NTCカガヤンへ |
| ARRL DXCCリストからCSVファイルを作るソフト (2024/12/11) | ||||
|---|---|---|---|---|
| ARRLのページにあるDXCCのファイル。 PDFファイルは見つけたのですがCSVファイルが見当たらない PDFをWORDに張るのにもMicrosoft 365 Personal」が月額1,284円が必要。 櫻井さんから教わったTEXTファイルをコピー&ペーストしたのですがExcelにうまく張れない ARRLのDXCCリストはこちら そこで先日以来はまっているPython(パイソン)で変換プログラムを作ってみることにしました。 |
||||
DXCClistからCSVファイルを作る.zip ダウンロード回数: 4 |
||||
| プログラムはPython(パイソン)というプログラミング言語で書いています。 動作確認をしたのはWindows11のパソコンですがpython-3.13.0-amd64をダウンロードしてインストールしておく必要があります。 Python(パイソン)のインストール後に外部ライブラーのインストールが必要です |
||||
|
これがARRLで見れるDXCCリスト。 ダウンロードできないのでコピー&ペーストでノートパッドなどに貼り付けてUTF-8でC:\Los\input.txtで保存  |
||||
| TEXTtoCVS.0.0.4.pyの実行画面 GUIベースでないところはお許しを。今勉ChatGPTで強中です 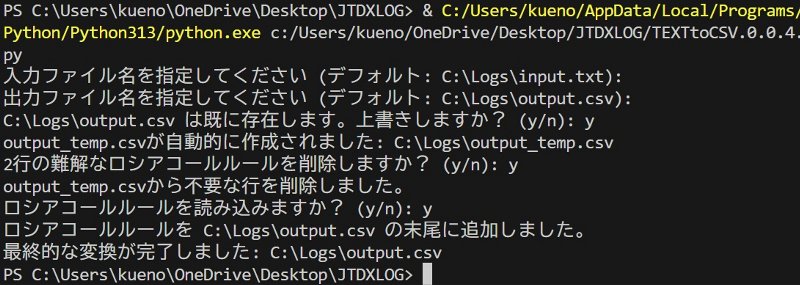 |
||||
| Readme.txt ARRLのDXCCリストのテキストバージョンからCSVファイルを作るためのソフトウェアです JI1FGX/DU9 Kouichi Ueno TEXTtoCSV.0.0.4.py TEXTtoCSV.0.0.4.pyを実行するためにはPythonのインストールが必要です。 Pythonのインストールは、公式サイト(https://www.python.org/downloads/)から行えます。 DXCCリストはこのURLにあります。 リンクが長いのでクリックしてください ダウンロードするかコピー&ペーストで input.txtの名前で フォルダーに保存してください。 下処理としてはヘッダー文章は削除してください。 保存ディレクトリはデフォルトでC:\Logsになっています。 適当に変えてください。 実行するとoutput.csvというファイルをデフォルトディレクトリに作ります。 テキストファイルに含まれている(数字)、*、#、^を取り除きCSVファイルを作ります。 ロシアのコールサインルールが分かりにくかったので独自にルールリストを作りました。 UA-UI1-7,RA-RZ* European Russia UA-UI8-0,RA-RZ* Asiatic Russia 同梱してあるファイル(全てのファイルはUTF-8で保存してください) TEXTtoCSV.0.0.4.py このプログラム input.txt ARRLからダウンロードしたテキストファイル output.csv 変換後のサンプルファイル Russia_Call_Rules.csv デフォルトデレクトリーに置いておいてください Readme.txt 開発裏話 プログラム自体はChatGPTが書いています。 私は仕様を伝えてそれに答える形でPythonのソースコードを送り返してきます。 機能追加や細かい修正も指示していきます。 テキストファイルからCSVへの変換や不要文字の削除などはものの数分でできました。 ところがDXCCリストに含まれているイレギュラーな文字を1文字消すのにChatGPTはてこずりました。 具体的には T8,(21) のカッコつきの、カンマの削除これはすぐに出来たのですが Z6(1),(55)このカンマを取るのに沢山のやり取りをしました。 この正規表現を書かせると必要なカンマまで消してしまうのです。 何度も正常な処理が出来るバージョンに戻しては書かせるの繰り返しに半日。 こちらから具体的な提案をしてやっと出来上がりました。 |
||||
ソースコード
|
||||